L'I.A.
L'Intelligence artificielle
Les réseaux de neurones.
Savoir comment fonctionne en gros l'intelligence artificielle basée sur les réseaux de neurones est nécessaire pour bien comprendre ce quelle est vraiment et quelles en sont les limites.
Contrairement à la programmation classique où les concepteurs d'applications donnent une série d'ordres précis à une machine, ici, c'est pratiquement la machine elle-même qui va déterminer ce qu'elle doit faire pour accomplir une tâche.
Et cela fonctionne de la façon suivante : un "neurone" est un petit module logiciel qui comporte une ou plusieurs entrées, qui accomplit une opération très simple selon certains paramètres (comparaison, addition...) et qui comporte une sortie correspondant au résultat de cette opération.
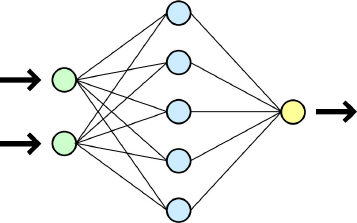
D'entrées en sortie, des dizaines de milliards de "neurones" sont ainsi connectés entre eux.
Pour "apprendre" à une machine équipée de ces réseaux de neurones à accomplir une tâche, il va falloir l'entraîner.
S'il existe plusieurs méthodes plus ou moins efficaces selon les tâches à accomplir (Machine Learning, Deep Learning...) , elles se résument le plus souvent à ces quatre opérations, sachant qu'au départ, les paramètres des "neurones" sont dans un état complètement aléatoire :
- Définir la tache, par exemple reconnaître un chat sur une photo
- Alimenter la machine avec un grand ensemble de données, par exemple des millions de photos avec ou sans chat
- Demander à la machine de dire si une photo comporte oui ou non un chat
- À chaque fois qu'elle se trompe, faire en sorte qu'elle modifie ses paramètres jusqu'à obtenir pratiquement 100% de réponses exactes.
La dernière opération peut être supervisée ou non par des humains, voire auto-supervisé par la machine elle-même ou par une autre machine.
Trois remarques à ce stade :
- Il est pratiquement impossible pour un humain de savoir comment fonctionne "in fine" cet ensemble de neurones.
- Si on peut arriver à 100% de bonnes réponses quand il s'agit de tâches qui doivent "comprendre" des règles très précises (Programmation, jeu d'échecs, recherche de date d'évènement...), il n'en est pas de même pour des tâches reposant sur une grande diversité de formes comme peuvent l'être des chats sur une photo ou sur une grande diversité de concepts comme on peut en trouver en économie ou en sociologie par exemple. La machine n'est donc que très rarement infaillible.
- Selon la façon dont on aura alimenté la machine en données, il peut y avoir des biais volontaires ou non. Les données peuvent être issues préférentiellement d'une culture, d'un genre, d'une classe sociale, d'une zone géographique plutôt que d'autres et les réponses s'en trouver affectées.
****
Grâce aux réseaux de neurones, les machines peuvent ainsi apprendre rapidement à exécuter un très grand nombre de tâches dans les limites que l'on vient d'évoquer.
Les plus connues d'entre elles sont sans conteste les tâches accomplies par les LLM (Large Language Model) qui, surtout depuis 2018, savent répondre à une question ou raconter une histoire en générant la suite de mots qui leur paraît la plus probable statistiquement au vu de ce que l'on peut trouver sur le sujet dans tout le Web. Le tout en quelques secondes quand cela vous prendrait des heures de recherches et de mises en forme fastidieuses.

C'est en novembre 2022 qu'Open AI lance une version gratuite de ChatGPT (Chat=Dialogue en ligne GPT=Generative Pre-trained Transformer) et rend l'utilisation de l'intelligence artificielle dite générative accessible au grand public.